Cafe Sales Data Cleaning and Exploration
This project focuses on cleaning and exploring a dataset of cafe sales transactions sourced from Kaggle. The primary goal is to demonstrate data cleaning and exploratory data analysis (EDA) skills using Python on a real-world dataset containing common data quality issues.
Dataset Link: http://kaggle.com/datasets/ahmedmohamed2003/cafe-sales-dirty-data-for-cleaning-training/data
The Dirty Cafe Sales dataset contains 10,000 rows of synthetic data representing sales transactions in a cafe. This dataset is intentionally "dirty," with missing values, inconsistent data, and errors introduced to provide a realistic scenario for data cleaning and exploratory data analysis (EDA). It can be used to practice cleaning techniques, data wrangling, and feature engineering.
Upon initial inspection, the dataset exhibited several data quality problems, including missing values (empty cells), inconsistent representations of missing information ("ERROR", "UNKNOWN"), and likely incorrect data types for certain columns.
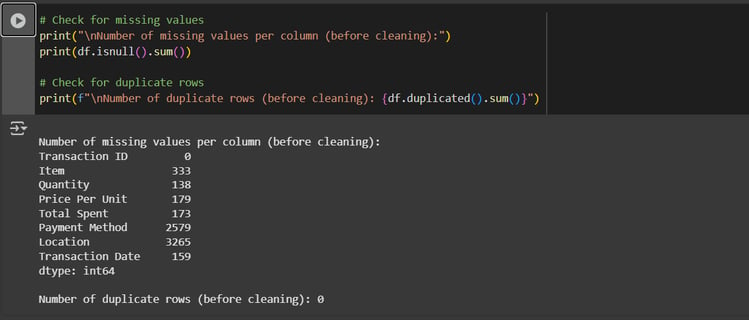
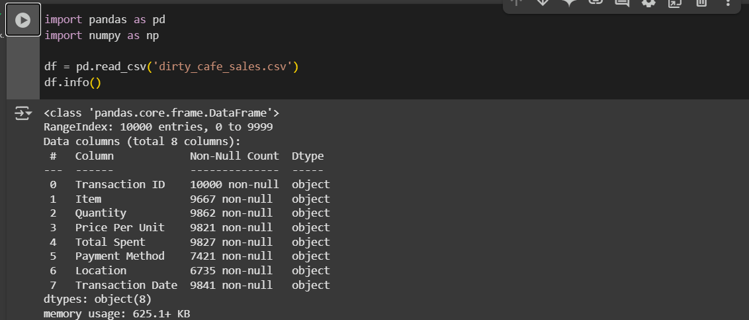
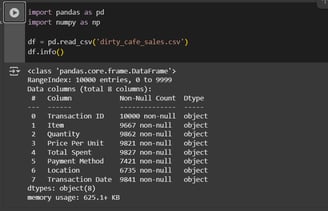
Using df.info() we can see the information about the number of columns, column labels, column data types, memory usage, range index, and the number of cells in each column (non-null values)
Print the first 5 rows of the dataset with print(df.head())
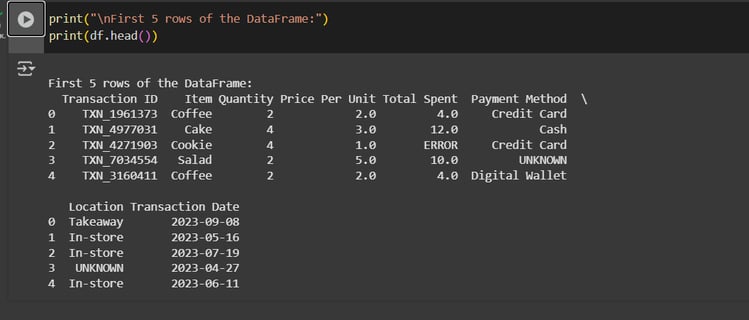
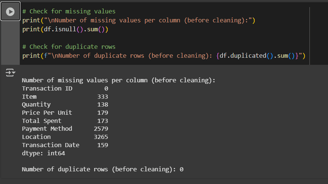
Check the missing values and the dublicates one.